บันทึกการทำระบบสำหรับโครงการ AI for Teachers ด้วย Supabase เพื่อรองรับการใช้งานพร้อมกันหลักหมื่นคน
บทความนี้ เกิดจากน้องจุ้นโพสต์ลงเพจ Prompt ไปวันๆ ว่า…
กำลังพิจารณาย้ายค่ายจาก Firebase -> Supabase มาคุยกันได้ในโพสนี้

เนื่องจากผมเพิ่งทำโปรเจคที่ใช้ Supabase อยู่พอดี ซึ่งมีคนใช้งานจริงพร้อมๆ กันเป็นหลักหมื่น… เลยมาคอมเม้นต์ตอบว่า
ทีแรกคิดว่าจะเล่าสั้นๆ แต่เขียนไปเขียนมาดันยาว เลยกลายมาเป็นบทความนี้แทนครับ
ตอนที่ 1: Project context
โปรเจคที่ทำเป็น Learning Management System (LMS) ที่มี target user ประมาณสองแสนคน สำหรับโครงการ AI for Teachers สอนทักษะ AI ให้กับข้าราชการครูทั่วประเทศไทยทุกสังกัด ฟรี เป็นความร่วมมือระหว่าง Microsoft Thailand, สสวท., สพฐ., ETDA, และทีมของ Novituz — ปกติผมแทบไม่ได้รับงานฟรีแลนซ์เลย แต่เห็นว่างานนี้ public benefit เลยตกลงช่วยทำ คิดว่าน่าจะได้ประสบการณ์เรียนรู้ใหม่ๆ ด้วย
โปรเจกต์นี้ผมได้รับผ่านหยก และก็ได้รับมาผ่านช้างอีกที หลังจากที่ทางทีมนั้นได้ลอง LMS ต่างๆ แต่ก็เหมือนจะไม่มีตัวที่โอเคพอในด้าน customization และราคา เลยได้ข้อสรุปกันว่า custom development น่าจะเวิร์คสุด หยกช่วยประสานงานกับทางทีมงานของ Novituz ส่วนช้างช่วยดูเรื่องการเตรียม infra เช่นโดเมนเนมกับ Azure resource ต่างๆ
โดยโปรเจคนี้เหมือนเป็น lightweight LMS โดย flow หลักคือ:
- ลงทะเบียนเข้าโครงการ ยืนยันอีเมล กรอกข้อมูลที่จะเอาไว้ใช้ในการออกเกียรติบัตรและวุฒิบัตร
- ลงทะเบียนเรียน ตามเวลาที่สะดวกเข้าเรียน โดยแต่ละหน่วยจะเปิดให้เรียน 2-3 รอบ
- เข้าเรียน (ดูผ่าน YouTube Live) โดยมีระบบ ลงชื่อเข้าเรียน และ บันทึกเวลาเรียน มีคลังเอกสาร (ก็คือลิงก์ไปไฟล์ PDF)
- ทำข้อสอบ หลังเรียนเสร็จครบโมดูล
- รับเกียรติบัตร หากสอบผ่าน
- รับวุฒิบัตร เมื่อเงื่อนไขครบถ้วน
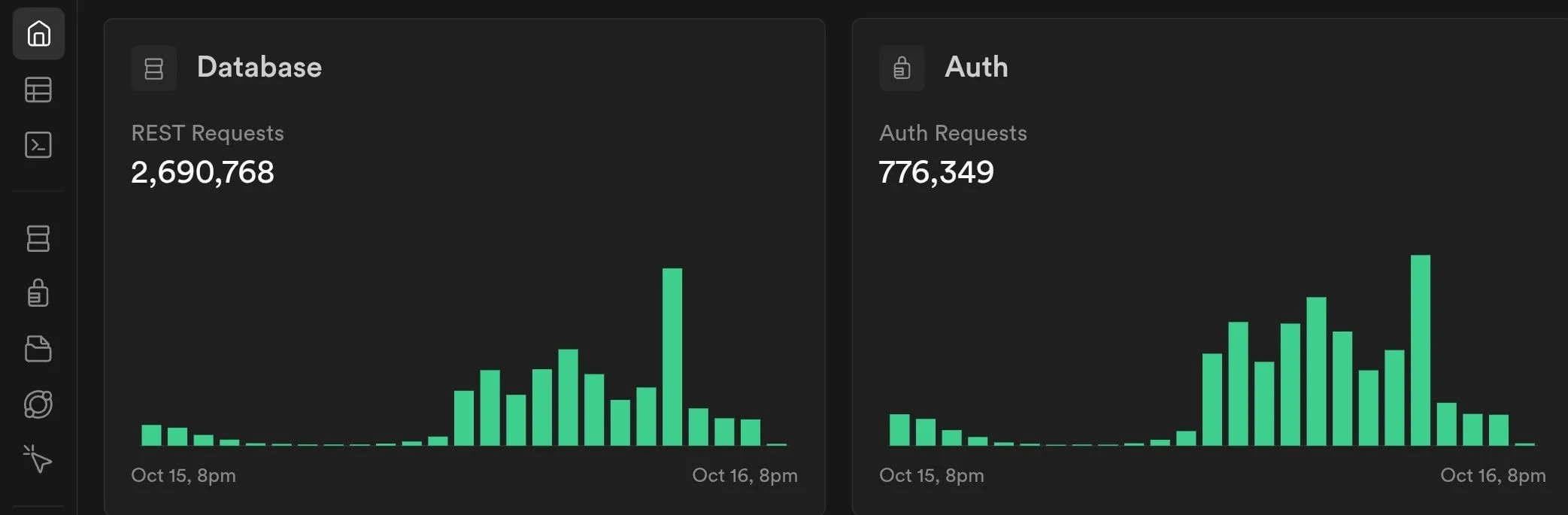
Architecture และภาษาที่ใช้:
- Frontend เป็น SPA Vite + Vue + Nuxt UI — deploy ขึ้น Cloudflare Pages
- Backend เป็น Supabase (client direct-to-DB) โดยใช้ Row Level Security ควบคุมการเข้าถึงข้อมูล และใช้ Postgres Function ในการ implement business logic บางส่วน (ก็คือ business logic ส่วนใหญ่เขียนเป็น SQL)
- Background jobs เขียนเป็น TypeScript รันบน Bun เอาไปรันบน VPS
ตอนที่ 2: Prototyping with Lovable
หลังจากที่คุยกันเบื้องต้น ก็เริ่มจาก prototype ดู — ยิ่งงานนี้เกี่ยวกับ AI ด้วย เลยคิดว่าเป็นโอกาสที่เราจะได้เรียนรู้เครื่องมือ vibe coding ใหม่ๆ
จากที่ดูตัวเลือกต่างๆ ก็เห็นว่าทั้งสองตัวนี้มี built-in Supabase integration:
- Lovable
- v0.dev
ก็เลยคิดว่าน่าจะได้ลองใช้ Supabase ด้วย
ช่วงนี้เห็นกระแส Lovable มาแรงมาก เลยเลือกใช้ Lovable ทำ prototype — ก่อนอื่นก็ขอให้ Lovable สร้างแอปให้ โดยบอกว่า เอาแค่ mockup มาก่อนนะ ไม่ต้องต่อ backend (ข้อมูล mock ทั้งหมด) แต่ในอนาคตเราจะ connect Supabase ในภายหลัง หากแอปที่ Lovable สร้างมาให้มันใช้ได้
ซึ่งขึ้นเวอร์ชันแรกมานี่ UI แทบจะใช้ได้เลย — ครบ loop หมด
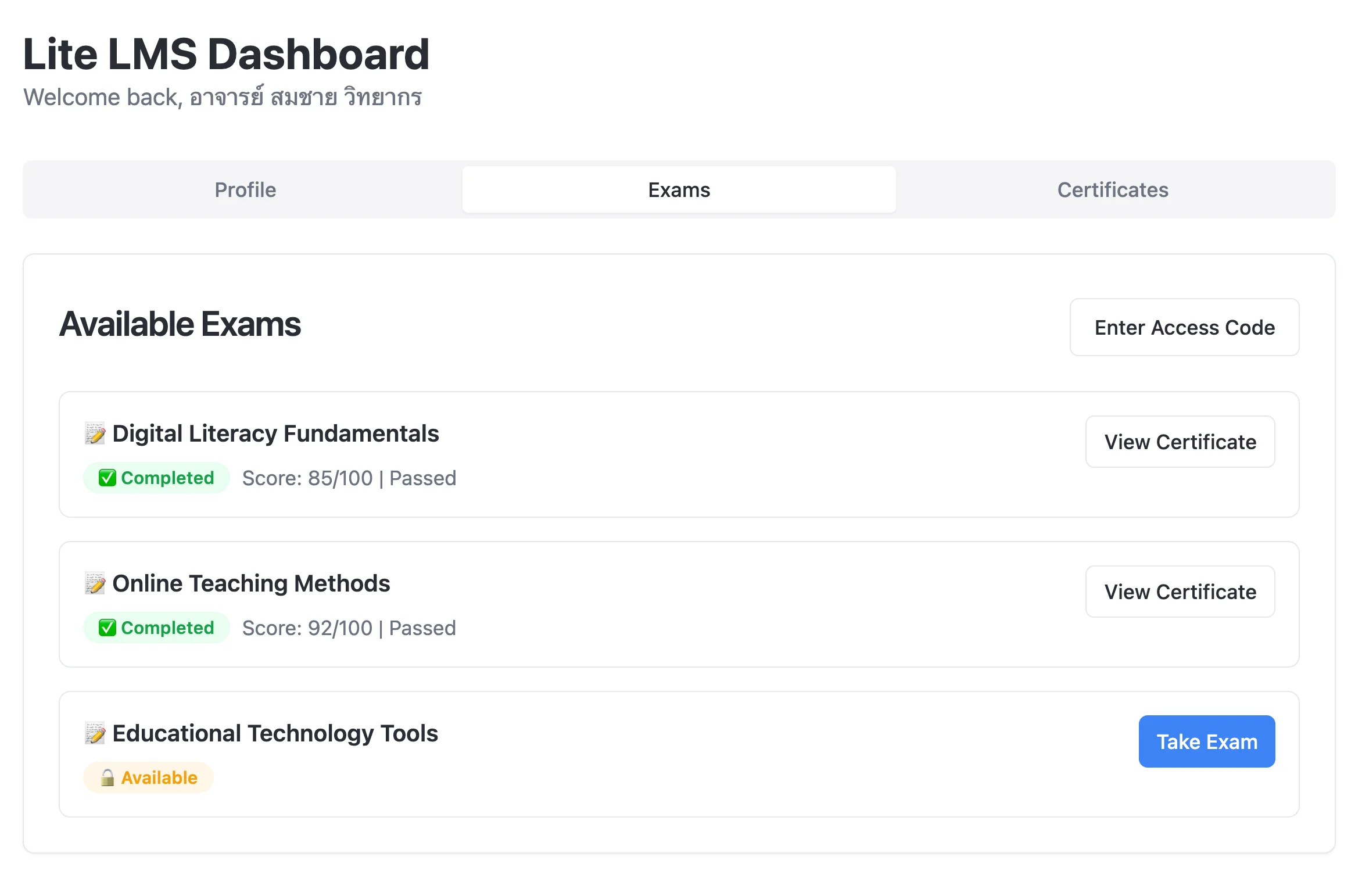
พอเห็นแบบนี้แล้ว ก็คิดว่าน่าจะเวิร์คดี ถ้าเกิดให้ Lovable ช่วย implement backend และ integrate ต่อให้ด้วยไปเลย … ก็เลยลุยเลย กด Lovable 25 เหรียญ แล้วก็สมัคร Supabase Pro อีก 25 เหรียญ
ตอนที่ 3: Beyond prototyping with Lovable
ผมเริ่มให้ Lovable ออกแบบ backend และช่วย integrate โค้ด React เข้ากับ Supabase แล้วก็ปรับหน้าตาแอปให้ดูดีขึ้น
กลายเป็นว่าผมใช้เครดิตมูลค่า $25 หมดภายในวันเดียว ตั้งแต่วันแรกที่ใช้งานเลย
นั่นก็เพราะว่า Lovable generate โค้ดที่ใช้ไม่ได้มาให้ (อาจจะสักทีละ 200-300 บรรทัด) ก็เสียเครดิตไปส่วนนึงแล้ว แล้วพอขอให้มันแก้ให้ถูกต้อง ก็เสียเครดิตเพื่อที่จะแก้อีก เครื่องมือ app generator ชอบ generate โค้ดมาทีละเยอะๆ ทำให้เปลือง token มากๆ
ปัญหาที่เจอก็มีหลายอย่าง…
ใช้ React แบบแปลกๆ
ตอน Lovable ขึ้นโปรเจค React ให้ มันก็ได้ติดตั้ง React Query ไว้ให้… แต่สุดท้ายก็ไม่ได้ใช้ กลายเป็นว่าเวลาดึงข้อมูลจาก database มา ก็เอาไปเก็บใน component state โดยใช้ useState กับ useEffect ตรงๆ ทำให้เกิดโค้ดที่ bug prone และมีโอกาสเจอ race condition ต่างๆ ได้ง่าย
ปัญหาด้าน Security
ถึงแม้ Lovable จะมีการ prompt engineer ให้สามารถทำงานกับ Supabase ได้ แต่รู้สึกว่าความรู้เรื่อง Supabase กับ Postgres มันค่อนข้างน้อยเหลือเกิน
Postgres DB ที่ Supabase ใช้ จะมีฟีเจอร์ด้านความปลอดภัยที่เรียกว่า Row Level Security โดยเราจะต้องเขียน Policy เพื่อกำหนดสิทธิ์การเข้าถึงข้อมูลในแต่ละตาราง
ปัญหาคือ Lovable สร้าง Policy ที่ไม่ secure เลย อย่างเช่น:
มี Policy นึง ชื่อมันบอกว่า “อนุญาตให้เฉพาะผู้ดูแลระบบสามารถแก้ไขข้อมูลได้” แต่พอเข้าไปดูจริงๆ กลายเป็นว่า มันเปิดให้ใครก็ได้สามารถแก้ไขข้อมูลได้ทั้งระบบ
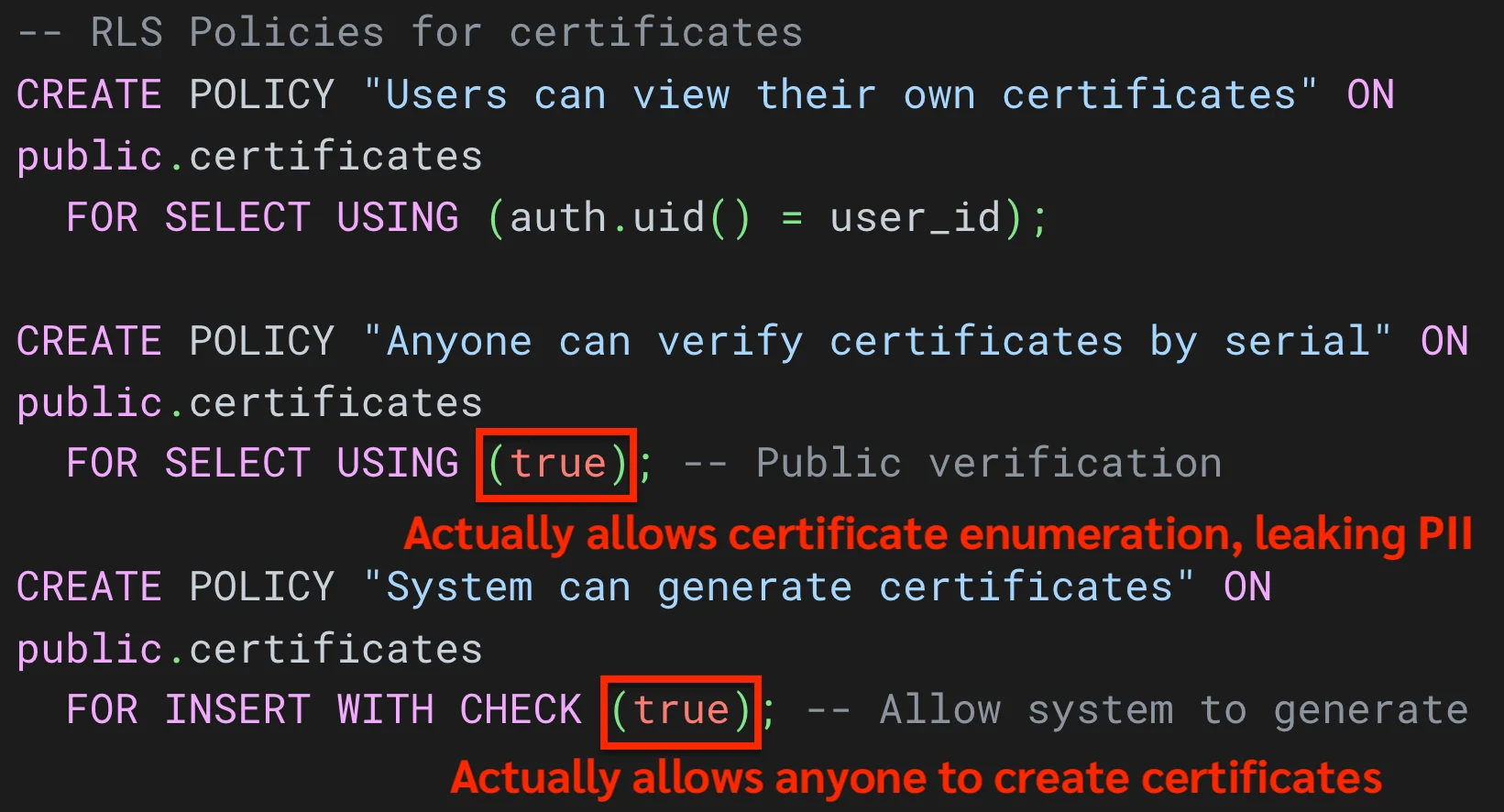
บาง Policy ก็เขียนมาแปลกๆ เช่น อนุญาตให้คนสามารถแก้ไขคะแนนข้อสอบของตัวเองได้
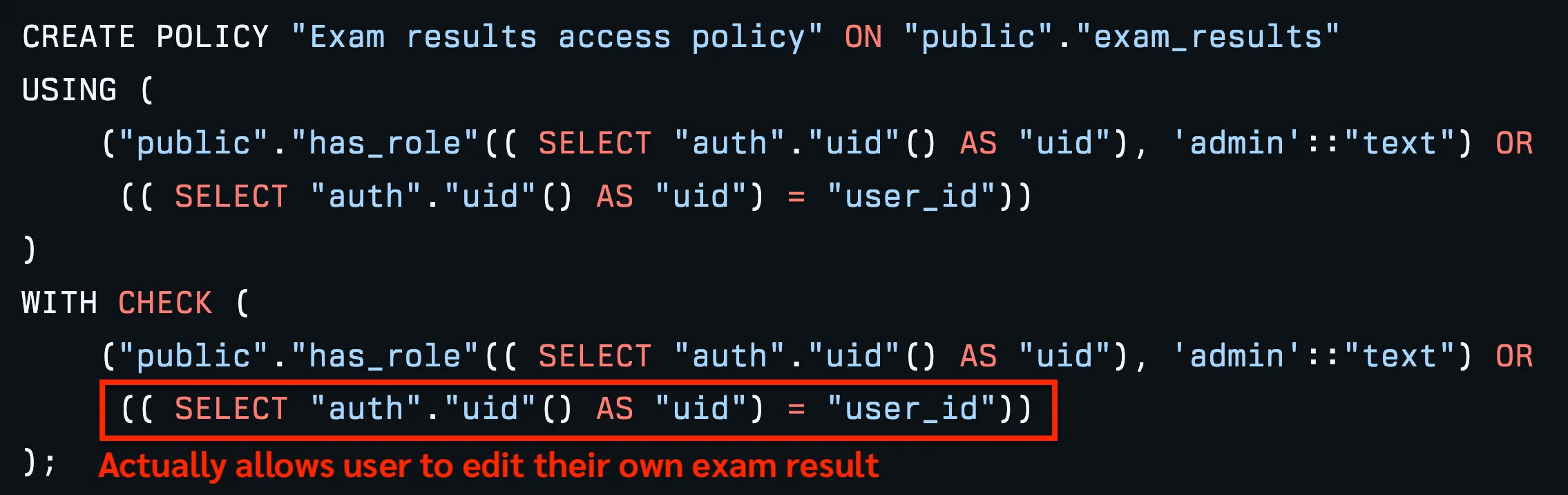
นอกจากนี้ Lovable บางทีก็เอาข้อมูลที่ sensitive มารวมอยู่ในตารางเดียวกับข้อมูลทั่วไป เช่น
เอา
is_adminไว้ในตารางprofilesตรงๆ ทำให้ user สามารถอัพเดตตัวเองให้กลายเป็นแอดมินได้เอาโค้ดสำหรับการบันทึกเวลาเรียน เก็บไว้ในตาราง
classesตรงๆ เนื่องจาก Security มันเป็นระดับ Row-Level ถ้าอ่าน Row ไหนก็ได้ ก็จะเห็นข้อมูลนี้หมด — ผมก็ต้องมาแก้ บอกให้มันแยกข้อมูลส่วนนี้ไปไว้ที่ตารางอื่นที่เข้าถึงได้เฉพาะแอดมิน
ฟีเจอร์ Security Review
ตัว Lovable มันจะมี feature ที่เรียกว่า “Security Review” คือเราสามารถกดขอ On-demand security review ได้ฟรี ซึ่งตรงนี้จะไม่เสียเครดิตอะไรเลย โดยมีการ integrate กับ Security advisor ของ Supabase ให้ด้วย แล้วก็สรุปมาว่ามีจุดไหนที่ต้องแก้บ้าง
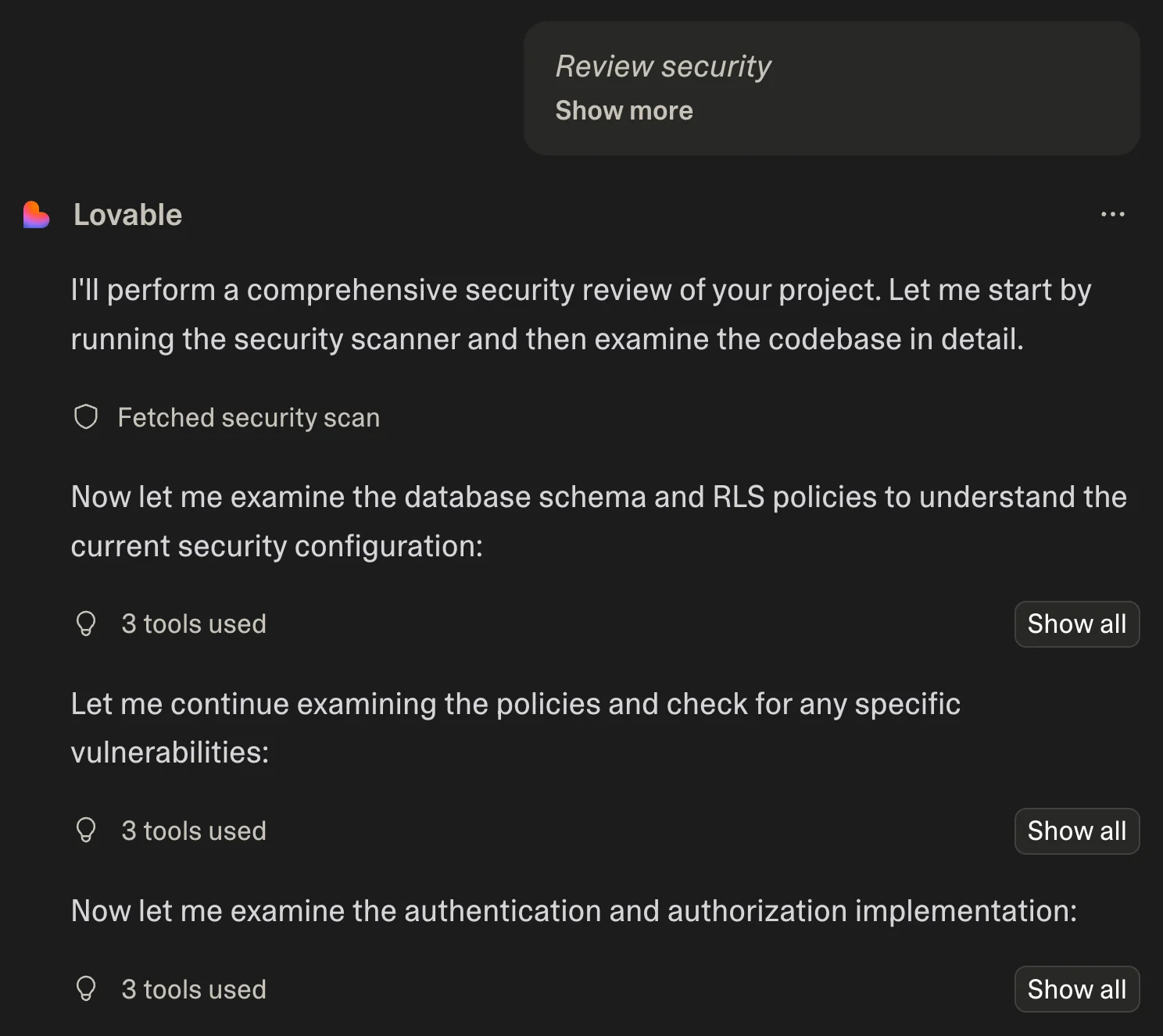
นอกจากนี้ถ้าเกิดระบบอัตโนมัติของ Lovable มันพบว่าโปรเจคเราอาจจะมี Security issue ปุ่ม Publish จะถูกแทนที่ด้วยปุ่ม Security Review (Free) แทนด้วย

ซึ่งก็ดูเหมือนว่าเออ เป็นแพลตฟอร์มการสร้างแอปที่ให้ความสำคัญด้าน Security อย่างมาก… แต่ปัญหาก็คือ:
ถึงการจะขอ Security review มันฟรี แต่พอกดแก้ก็ใช้เครดิตอยู่ดี คือต้องจ่ายเงินให้มันสร้างโค้ดที่ไม่ปลอดภัย แล้วก็จ่ายเงินให้มันแก้งานของตัวเองอีก
ช่องโหว่ที่ User สามารถแก้ไขคะแนนข้อสอบของตัวเองได้ อันนั้นผมเจอเอง — คำสั่ง Security Review กดไปหลายรอบก็ไม่สามารถตรวจจับปัญหาใน Policy นี้ได้เลย อาจจะเพราะมันเชื่อใจชื่อของตัว Policy มากเกินไป
ปัญหาด้าน Performance
Supabase มันสามารถ optimize query ได้หลายวิธีมาก (เช่น สร้าง Postgres view, Postgres function หรือแม้แต่ Denormalization) เพื่อให้ฝั่ง client สามารถขอข้อมูลที่ต้องการจาก DB ได้เลย แต่ Lovable แทบไม่ได้ใช้ท่าพวกนี้เลย
ตัวอย่าง: สร้างหน้าสรุปข้อมูล ว่าแต่ละคลาสมีคนลงทะเบียนเรียนกี่คนบ้าง
ปกติแล้ว Supabase จะปิดฟีเจอร์ aggregation ไว้ เพราะเสียง Denial-of-Service attack แต่ถึงไม่สามารถ aggregation ผ่าน JS SDK ก็มีวิธี query ให้ performant ได้หลายวิธี เช่น:
- สร้าง Postgres view หรือ Postgres function ที่ทำหน้าที่ aggregate ข้อมูลมาให้ (ปกติใช้ Firebase จะไม่มีท่านี้ ทำได้แค่ denormalize ข้อมูล)
- Denormalization: สร้างตารางขึ้นมาเก็บข้อมูลนี้ไว้เลย (เช่น
class_enrollment_summaryที่มีแค่class_idกับenrollment_count) แล้วก็ใช้ Trigger ใน Postgres คอยอัปเดตข้อมูลตรงนี้อีกที
สิ่งที่ Lovable ทำเวลาต้อง query ซับซ้อนแบบนี้ เท่าที่เห็นคือออกมาสองท่า:
- ดึงข้อมูลทั้งหมดมาในฝั่ง client แล้วค่อยเอาไปนับเอง
- ทำ N+1 queries ที่ฝั่ง client-side คือดึงข้อมูลคลาสมาก่อน แล้วค่อยไล่ดึงข้อมูล enrollment ของแต่ละคลาสแยกกัน
ทีแรกก็ไม่ได้สนใจโค้ดที่ Lovable มัน generate มามากนัก… แต่ไปๆ มาๆ เห็นหน้า backoffice มันเริ่มช้า พอเปิด Network inspector ขึ้นมาดูแค่นั้นแหละ ข้อมูลหน้านี้คือยิง HTTP request ~300 request แล้วเอาผลลัพธ์มาประกอบกัน
หลงๆ ลืมๆ
ตอนที่ผมเริ่ม implement ระบบ ผมเล่า business rule ต่างๆ ให้ Lovable ฟังเยอะมาก (เพราะจะได้เป็น context ไว้ให้ช่วยในการตัดสินใจเมื่อถึงเวลา implement feature) — แต่กลายเป็นว่า พอเวลาผ่านไปสักพัก Lovable ก็ลืมสิ่งที่ผมเล่าให้ฟังตอนต้นไปหมด (น่าจะหลุดจาก context window) ซึ่งปัญหานี้แทบไม่เจอเลยเวลาใช้ Claude Code
Claude Code มีฟีเจอร์ To-do list แต่เหมือน Lovable จะไม่มี ยิ่งทำให้หลงลืมได้ง่ายขึ้น เวลาขอให้ทำหลายๆ อย่าง หรือทำอะไรซับซ้อน พอทำไปสักพัก ก็เริ่มลืมว่าต้องทำอะไรต่อ หรือเป้าหมายหลักคืออะไร
บางทีขอให้ปรับโครงสร้างฐานข้อมูล — มันสร้างตารางใหม่มา แต่ลืมลบตารางเก่าออกหลังจากนั้น ทำให้ข้อมูลอยู่หลายที่ และพอผ่านไปสักพักก็ลืมว่าที่ไหนคือ authoritative source of truth
ตอนขึ้นโปรเจค Lovable เลือกใช้ Bun แต่ทำไปสักพักก็ลืม แล้วเริ่มติดตั้ง dependencies ด้วย
npmแทน ทำให้โปรเจคมีทั้งไฟล์bun.lockbและpackage-lock.jsonอยู่ด้วยกันแต่เท่าที่ลอง รู้สึกว่าข้อดีของ Lovable คือ มันอยู่กับปัจจุบันได้ดีมาก — ถึงมันจะลืมเรื่องในอดีตได้ง่ายดาย แต่มันสามารถ analyze โค้ดปัจจุบันที่มีอยู่ได้ดีมากๆ — ผมรู้สึกว่าเวลาใช้ Lovable ให้เวิร์คสุด จะต้องขอให้มันทำทีละอย่างไปเลย (ซึ่งต่างจาก Claude ที่เราสามารถถามหลายๆ อย่างพร้อมๆ กันได้เพื่อประหยัด token)
การตัดสินใจทิ้ง Prototype
สุดท้ายก็… นั่นแหละครับ เครดิต $25 หมดไปในวันเดียว… แต่อย่างน้อยเราก็ได้ Database schema ไปเวิร์คต่อ
หลังจากที่เครดิตหมดผมก็ Export โปรเจกออกมา แล้วเอามาทำต่อเอง ก็พบว่าโค้ดที่ได้มามันไม่ต่างจากโค้ดที่มือใหม่ React จะเขียนเลย — เหมือนต้องมาทำงานกับโปรเจค brownfield ทั้งๆ ที่เป็นโปรเจค greenfield แท้ๆ
นอกจากนี้ โลกของ React เนี่ยมันก็ยังเปลี่ยนไปเรื่อยๆ เยอะมาก ยังมีท่าใหม่ๆ ออกมาเรื่อยๆ เช่น Server Component, Server Functions, ฯลฯ
สุดท้ายผมเลยทิ้งโค้ด Frontend เก็บ Database schema ไว้ แล้วย้ายไปสร้างแอปใหม่ด้วย Vue กับ Claude Code แทน
ตอนที่ 4: Why not Firebase?
ตอนแรกผมก็เลือกอยู่เหมือนกันว่าจะใช้ Firebase หรือ Supabase ดี
ประสบการณ์กับ Firebase
ส่วนตัวผมชอบ Firebase มากๆ และเคยใช้มาหลายงานมาก
ผมเคยทำโปรเจกต์ที่มีข้อมูลแบบ real-time มีคนใช้งานหลักร้อยถึงหลักพันคนพร้อมๆ กัน และมีการอัปเดตข้อมูลอยู่ตลอดเวลา (conference companion app, interactive art, audience engagement) ผมไม่เคยเจอปัญหาแอปล่มเพราะ Firebase เลย — แต่ก็ยังไม่เคยใช้ในสเกลหลักแสนคน
Denial-of-wallet
ผมมั่นใจว่า Firebase น่าจะรองรับโหลดได้อยู่… ถ้าแต่ค่าใช้จ่ายมันจะบานไหม?
ผมเคยโดน Firebase ส่งเมลมาเก็บเงินเพราะลืมใส่ dependency array ใน useEffect ทำให้เกิดการเรียก API ไปที่ Firebase ตลอดเวลา จนค่าใช้จ่ายพุ่งไปสิบๆ เหรียญในไม่กี่ชั่วโมง
Vendor lock-in
แล้วถ้าเกิดค่าใช้จ่ายมันบานแล้วเราควบคุมไม่ได้ ด้วยความที่เป็น proprietary platform โปรเจคเราก็ติดแหง็กอยู่กับ Firebase จะย้ายก็จะย้ายไป service อื่นก็ไม่ได้ ก็ต้องยอมจ่ายเงิน
Control
สุดท้ายก็เลยคิดว่า ในสเกลนี้ เราต้องเลือกอะไรที่เราอย่างน้อยเราก็ in control ได้ในระดับนึง ก็เลยเลือก Supabase โดย:
จะเริ่มใช้ hosted service (Supabase Pro) ไปก่อนเพื่อความสะดวก และอย่างน้อยก็จะได้สนับสนุน open source ด้วย
แต่ถ้าเกิดค่าใช้จ่ายในการใช้งาน Supabase กับทางนั้นมันแพงจนไม่ make sense (ซึ่งจะพูดถึงในตอนต่อๆ ไป) เราก็พร้อมจะย้ายระบบทั้งหมดมารันบน VPS
ตอนที่ 5: Supabase Auth
ราคา
อย่างแรกที่เอ๊ะ ก็คือเรื่องราคา — คือ Supabase Pro ($25) เนี่ย มันให้ monthly active user ฟรีแค่ 100,000 user แรกเท่านั้น ส่วนเกินนั้นจะคิดค่าใช้จ่ายประมาณคนละ 0.1 บาท
ซึ่งแปลว่า ถ้าเกิด MAU สองแสนคนจริงๆ ก็จะมีค่าใช้จ่ายสำหรับ Auth บวกมาเดือนละ 20,000 บาท ซึ่งส่วนตัวก็รู้สึกไม่ค่อย make sense เพราะว่า technically แล้ว user มันก็แค่แถว 1 แถวใน database เอง (ขนาด Firebase ยังไม่คิดค่า MAU เลยด้วยซ้ำ)
ซึ่งที่ตัดสินใจใช้ Supabase ต่อ ก็เพราะว่าถ้าเกิด user แล้วเริ่มใกล้แสนคนจริงๆ เราก็แค่ย้ายมา self-host
SMTP
เดิมตั้งใจว่าจะให้ user log in ด้วยอีเมลแบบ passwordless — โดยระบบจะส่ง OTP ไปให้ user เอามากรอกเพื่อยืนยันอีเมลตัวเอง
เรื่องที่ไม่คาดคิดอย่างที่ 2 คือเรื่องอีเมล OTP — พอทำจริงๆ ไปดู Docs ก็พบว่า บริการส่งอีเมลของ Supabase ตัวเริ่มต้นมันมี rate-limit หนักมาก เขาบอกว่าห้ามใช้กับ production ถ้าจะใช้กับ production ต้องไปสมัครบริการ SMTP อื่นมาใช้แทน
ณ จุดนี้ จะไปสมัครบริการ SMTP ใหม่ ก็ต้องเริ่มจาก Rate Limit ต่ำๆ เพื่อ build reputation ก่อน แทบเป็นไปไม่ได้เลยที่จู่ๆ จะให้ user สองแสนคนมาใช้บริการทันที
(ปัญหาเรื่องการส่งอีเมล เป็นเรื่องที่ไม่เคยต้องคำนึงถึงเลยสมัยใช้ Firebase Auth แต่มันก็มี rate limit รายวันอยู่)
หลังจากที่ปรึกษากับทีม สุดท้ายก็ได้ความว่า โอเค งั้นเราบังคับให้ใช้ OAuth ผ่าน Microsoft Account หรือไม่ก็ Google Account แทน ปัญหาเรื่อง Auth ตรงนี้ก็หมดไป และ Supabase เขียน Docs ตรงนี้ไว้ดีมาก
API deadlock
มีอยู่จุดนึงที่จู่ๆ Auth SDK ของ Supabase มันไม่ return ค่าอะไรกลับมาเลย คือพอเรียกใช้เมธอดเช่น supabase.auth.getUser() เราได้ Promise ที่มันไม่ resolve ไม่ reject แต่ทำให้แอปค้างไปเลย
ผมก็งงว่าเราเขียนโค้ดอะไรผิด จนต้องไปขุดโค้ดของตัว Supabase JS จนเจอ debug flag (ที่ไม่ได้ document ไว้) เสร็จแล้วพอเปิดก็เลยมาเจอกับโค้ดที่ทำหน้าที่ manage concurrency lock ระหว่างหลายๆ แท็บ ซึ่งโค้ดใน @supabase/auth-js มัน acquire lock โดยไม่มี timeout จนเกิดเป็น deadlock — สรุปว่าผมไม่ได้เขียนโค้ดอะไรผิดเลย แต่เป็นบั๊กที่ตัวไลบรารี่ ตอนนั้นผมเดือดมาก ไม่คิดเลยว่า professional auth solution ที่เราจ่ายเงินใช้ จะ publish โค้ดอะไรแบบนี้มาให้คนไปปล่อยบน production…
ผมขุดโค้ดเพิ่มเติมจนเจอ workaround แล้วก็เอาไปเปิด issue แจ้งว่ามันมีปัญหานี้นะ ซึ่งต่อมาก็มี dev ที่อื่นอีกสามคนมาคอมเมนต์ว่า
- ขอบคุณสำหรับ workaround เพราะเจอปัญหานี้เหมือนกัน
- เราเสียเวลากับปัญหานี้ไปแล้ว 2 ชั่วโมง (จนกระทั่งมาเจอ issue นี้)
- ผมเอาหัวโขกกำแพงกับบั๊กนี้มาทั้งวัน ขอบคุณที่แจ้งบั๊กนี้
ตอนนี้ผ่านมา 1 เดือนแล้ว ยังคงไม่มีใครจากทีม Supabase มาตอบ
…แต่นอกจาก 3 ประเด็นนี้ Supabase Auth ใช้ได้ดีมากครับ
ตอนที่ 6: Supabase Postgres
ส่วนตัวผมชอบแนวคิดของ Supabase มาก คือสร้างทุกอย่างบน Postgres
ตัว Supabase เนี่ยแทบจะไม่ได้ abstract Postgres ออกไปจากเราเลย — เวลาเราสร้างโปรเจกต์ เราก็จะได้ connection string ที่สามารถต่อไปที่ database ได้ตรงๆ (dedicated Postgres instance)
และเรื่องพวก Authentication & Authorization อะไรต่างๆ ก็ไม่ได้ reinvent the wheel แต่ใช้สิ่งที่ Postgres มีอยู่แล้วให้เกิดประโยชน์มากที่สุด
ผมชอบมากๆ เพราะว่าถ้าเราใช้ Supabase จนคล่อง มันก็เหมือนกับเราใช้ Postgres เก่งขึ้นด้วย ซึ่งก็พบว่าเป็นเช่นนั้นจริงๆ
ทีนี้เนี่ย เวลาเว็บแอปพลิเคชันของเราจะเรียกข้อมูลหรือแก้ไขข้อมูลใน database สำหรับโปรเจกต์ที่เป็น Supabase ก็ทำได้ 2 วิธีหลักๆ
วิธีที่ 1: ทำแบบ Traditional Web Application
Frontend เรียก Backend → Backend จะเช็คสิทธิ์ต่างๆ เสร็จแล้วจึงไปคุยกับ database ต่อ
ความปลอดภัยของแอปก็จะขึ้นอยู่กับความปลอดภัยของโค้ด Backend ซึ่งปกติก็จะเขียนด้วย TypeScript โดยใช้ Supabase Edge Function
แต่ถ้าดูใน Pricing ก็จะเห็นว่า Edge Function เนี่ยมันมีจำกัดจำนวนครั้งเรียกใช้งานได้ ถ้าใช้เกินนั้นก็จะขึ้นอยู่กับว่าเราเปิด Spend Cap ไว้หรือเปล่า
- ถ้าเปิดไว้ back-end เราก็จะหยุดทำงาน
- ถ้าไม่เปิด มันก็จะชาร์จตังค์เราเพิ่ม
ซึ่งผมก็ต้องคิดหนัก เพราะว่า free quota มันแค่ 2 ล้านครั้ง ถ้า user มีสองแสนคนจริงๆ เรียกใช้ Edge Function คนละ 10 ครั้ง ก็หมด quota แล้ว
สุดท้ายจึงเลือกที่จะไม่ใช้ Edge Function ในการ implement business logic ของระบบ
วิธีที่ 2: Front-end คุยกับ Database ตรงๆ
Postgres มี extension ชื่อว่า PostgREST ที่ทำให้ฐานข้อมูล Postgres สามารถเรียกใช้งานได้ผ่าน REST API ซึ่ง Supabase ก็เอา PostgREST มาใช้ และสร้าง JavaScript SDK ให้ Frontend เราเรียกได้ตรงๆ
พอไม่มี backend มาเป็นตัวกลางแล้ว หน้าที่ในการดูแลความปลอดภัยของข้อมูลก็จะตกไปอยู่ที่ฝั่ง database แทน
ผมชอบวิธีนี้ เพราะว่า:
- มันช่วยให้เราตัดเลเยอร์นึงออกจากระบบเราไปได้ ซึ่งก็ช่วยลดงานตรงส่วนนี้ไปได้
- Supabase เองไม่ได้จำกัดจำนวนครั้งที่เรียก PostgREST เหมือนกับ Edge Function
แต่ใครที่ยังไม่ชินกับ architecture แบบนี้ ก็อาจจะลืมคิดเรื่องความปลอดภัย ลืมกำหนด Policy ต่างๆ ให้ดีๆ จนเกิดปัญหาข้อมูลรั่วไหลได้ (เป็นปัญหาความเสี่ยงที่ Firebase ก็มีเหมือนกัน ซึ่งก็มีข่าวเรื่องข้อมูลรั่วไหลเพราะไม่ได้ตั้งค่า Security Rules ให้เห็นเรื่อยๆ)
แปลว่า business logic หลายๆ อันของระบบนี้เนี่ย แทนที่จะเขียนเป็นภาษา TypeScript ก็ต้องไป implement เป็นภาษา SQL แทน โดยทำได้หลายท่า:
- Postgres Function (สำหรับ logic ซับซ้อนหลายขั้นตอน สามารถเรียกได้โดยใช้
supabase.rpc()) - Postgres View (สำหรับ query ที่ซับซ้อนเกินที่จะใช้ PostgREST query builder ได้ เช่นเวลาต้องการ aggregate ข้อมูล)
- Row Level Security Policy (สำหรับกำหนดสิทธิ์การเข้าถึงข้อมูล)
ซึ่งการเขียน business logic เป็นภาษา SQL เนี่ยก็ไม่ใช่เรื่องง่าย สมัยก่อนผมก็เคยพยายามทำ แต่ว่าก็ล้มเลิกไปเพราะว่ามันไม่ชินเลย แต่เดี๋ยวนี้ AI สามารถเขียน Postgres Function ให้แม่นยำมากๆ และโค้ดที่มันเขียนมา เราก็อ่านค่อนข้างรู้เรื่อง ถึงแม้ว่ามันจะยาวกว่าเมื่อเทียบกับเขียนใน TypeScript ก็ตาม
ตอนที่ 7: Infrastructure
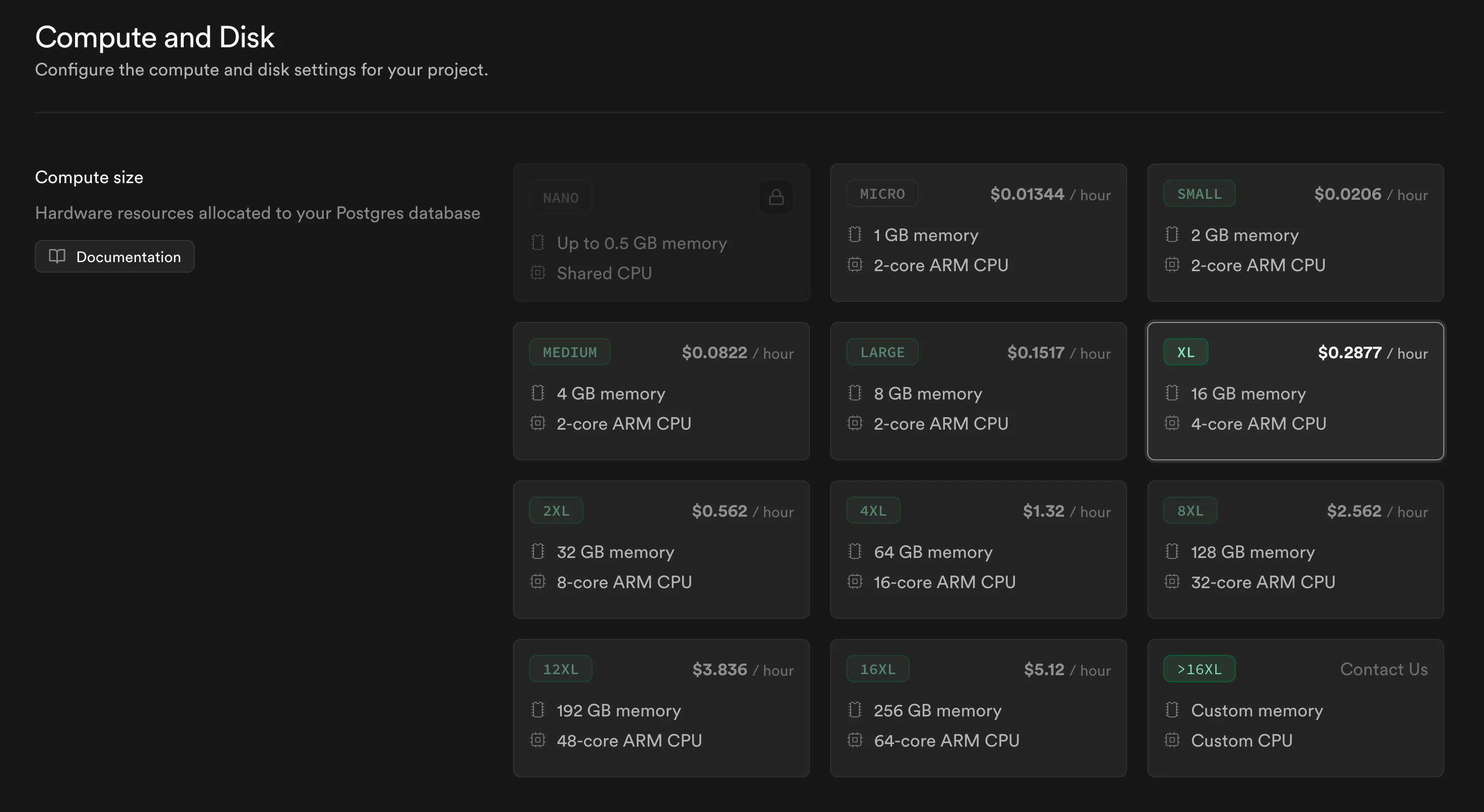
ตัว pricing model ของ Supabase เนี่ย ก็คือเราจ่าย $25 เพื่อใช้ Supabase Pro แต่ว่าพอเราจ่ายแล้วเราจะพบว่าเราจะได้ compute size ระดับ Micro
- CPU: 2 shared core
- RAM: 1 GB
ค่าใช้จ่ายก็จะคิดแบบเหมารายชั่วโมงเลย (ไม่ต้องกลัวเรื่อง bill shock) แต่ถ้าคนใช้งานเยอะเกินที่ compute เรารับไหวเว็บก็ล่ม
คราวนี้ก็ต้องมาดูว่า compute size ระดับไหนที่จะสามารถรองรับโหลดของเราได้
Shared core (burstable)
Compute size ระดับที่เล็กกว่า Large จะเป็น Shared CPU แปลว่ามันจะมี baseline performance ของมันอยู่ แต่หากจำเป็นต้องใช้ compute เยอะๆ ระบบจะอนุโลมให้มีการ burst ได้แป๊ปนึง ก่อนที่จะระบบจะ throttle ให้ CPU กลับมาอยู่ที่ baseline performance
แปลว่าที่เราเห็นเว็บมันเร็วๆ เวลาคนใช้ยังไม่เยอะเนี่ย อาจจะเพราะปริมาณ compute รวมของเรา ยังอยู่ใน burst limit แต่ถ้าข้ามเส้นนั้นเมื่อไหร่คือระบบจะช้าเป็นเต่าไปเลย
ในวันที่มีคลาสแรก (ที่จะมีคนเข้ามาหลักหมื่น) ผมจึงไม่กล้าฝากระบบไว้กับ Shared CPU เลย จึงอัปเกรด compute size ให้เป็น Dedicated CPU แทน ซึ่งราคาเริ่มต้นที่ $110 ต่อเดือน (ยังดีที่คิดเป็นชั่วโมง)
จากที่ลองใช้งานจริงมา พบว่า Compute Size L ก็ยังไม่พอที่จะรับโหลด ช่วงที่ peak load ทำให้เว็บมันหน่วงไปประมาณ 5 นาที จึงต้องอัพเกรดเป็น XL ($210 ต่อเดือน)
Downtime
อีกเรื่องที่รู้สึกแปลกๆ เวลาใช้ Supabase Postgres คือ เวลา upgrade compute size จะมี downtime ประมาณ 5 นาที ที่รู้สึกแปลกก็เพราะว่าที่เคยใช้ AWS RDS หรือ Digital Ocean Managed Databases เนี่ย มัน upgrade ได้โดยไม่มี downtime เลย
Point-in-Time Recovery
นอกจากนี้ Amazon RDS และ Digital Ocean Managed Database สามารถทำ Point-in-time recovery ที่เราสามารถย้อนสถานะของ database ย้อนกลับไปยังวินาทีไหนก็ได้ ในช่วง 7 วันที่ผ่านมา
แต่บน Supabase Postgres ถ้าอยากทำ Point ต้องจ่ายเพิ่ม $100/เดือน แต่ถ้าไม่จ่าย ก็จะมี backup เป็นรายวันเท่านั้น
Single Point of Failure
และอีกปัญหาหนึ่งของการที่ทุกอย่างรวมถึง authentication มาอยู่บน PostgreSQL ก็คือ PostgreSQL กลายเป็น single point of failure
ถ้าเกิดเรา query ข้อมูลจาก database หนักจนมันล่ม ระบบ authentication มันก็จะล่มไปด้วย (ต่างจาก Firebase ที่ Auth กับ Database แยกกันโดยสิ้นเชิง)
ตอนที่ 8: Schema Migration
ด้วยความที่ Supabase มัน build on top of Postgres ตารางต่างๆ จะมี schema ชัดเจน ฉะนั้นเราก็ต้องมีระบบในการ migrate database schema
ปัญหาคือรู้สึกส่วนตัวรู้สึกว่า migration tooling ของ Supabase เนี่ยมันไม่ค่อยครบเลย
คือ Supabase เนี่ยมันมี CLI ที่เอาไว้สร้างและ apply migration ต่างๆ แต่ migration เราสามารถ apply ได้ทางเดียว (คือ apply ไปข้างหน้าได้ แต่ roll back ไม่ได้)
จากที่อ่านๆ ใน issue คือฝั่ง Supabase ก็เหมือนแนะนำว่า มีฟีเจอร์ database branching ทำให้สามารถ safely experiment with schema changes ได้โดยไม่กระทบ DB หลัก (แต่คิดเงินเพิ่มนะ branch ละ $10/เดือน คิดเป็นรายชั่วโมง)
เลยรู้สึกว่า Supabase CLI มันค่อนข้าง rudimentary มันทำอะไรได้ไม่ค่อยมาก ถ้าเลือกใช้ก็จะใช้ไม่ค่อยสะดวก เมื่อเทียบกับเครื่องมือที่ช่วยให้เราเขียน schema ได้แบบ declarative (เช่น Prisma หรือ Drizzle)
แต่ด้วยความที่เราสามารถ access Postgres database ได้ตรงๆ เราก็ไม่ได้จำเป็นต้องใช้ Supabase CLI ในการทำ schema migration… แต่การใช้ Supabase CLI มันก็มีข้อดี เพราะ CLI มันสามารถ apply migration ลงบน production ให้เราได้เลย โดยที่ไม่ต้อง setup tooling เพิ่มเติม แต่ฟีเจอร์มันก็จะจำกัดจนขัดใจแบบนี้ ก็เป็น trade-off
Views, Functions, Policies
ปกติเวลาเราทำ traditional web application แบบดั้งเดิมที่ต้องมี backend มาคั่น ปกติเราก็จะ deploy แค่พวก DB schema change ต่างๆ (เช่น tables กับ indexes) ผ่าน migration tool
แต่พอเราใช้ Supabase กับ PostgREST ทำให้มีของที่เราต้อง deploy เพิ่มเติม:
- Views
- Functions
- Policies
ซึ่งของการ deploy ของพวกนี้ด้วยเครื่องมือ migration ผมรู้สึกว่ามีปัญหามากๆ (คนใน Reddit ก็เจอปัญหาเช่นกัน) อย่างเช่น ทุกครั้งที่เราจะ deploy function ใหม่ เราก็จะต้องสร้างไฟล์ migration ใหม่เลย ผลก็คือ
- เวลาเราแก้โค้ดของฟังก์ชัน แม้เพียงแค่ 1 บรรทัด เราก็ต้องสร้าง migration ใหม่เพื่อเอาฟังก์ชันใหม่ไปทับฟังก์ชันเก่า
- เวลาเรา search โค้ดเพื่อหา implementation ของฟังก์ชัน Postgres ใดๆ เราจะเจอฟังก์ชันทุกเวอร์ชันที่เราเคยเขียนมาอยู่ในโค้ดเบส
- เวลารีวิวโค้ด เราจะไม่เห็น diff เลยว่าฟังก์ชันเปลี่ยนแปลงอะไรบ้าง เพราะเราจะเห็นโค้ดฟังก์ชันทั้งก้อนที่ถูกเขียนทับมาใหม่
ซึ่งก็มีคนเคยทำเครื่องมือ srtd มาช่วยให้เราสามารถ define Postgres function แล้วก็ view ต่างๆ แบบ declarative ได้ แต่เครื่องมือนั้นก็ไม่ได้ maintain แล้ว ผมเลยไม่กล้าฝากความหวังไว้กับมัน
Prisma/Drizzle
อีกท่าก็คือการใช้ ORM ที่มี migration tool มาให้ เช่น Prisma หรือ Drizzle แล้วต่อไปที่ Postgres โดยตรง โดยไม่ต้องใช้ Supabase CLI
แต่ Prisma กับ Drizzle มันออกแบบมาสำหรับการทำงานกับ traditional web application เลยขาดฟีเจอร์ที่จำเป็นสำหรับการทำงานกับโปรเจค Supabase…
- Prisma ไม่สามารถจัดการ Row Level Security Policy ได้ ไม่ซัพพอร์ตการ declare Postgres Function และ ณ เวลาที่เขียน Views ยังคงเป็น preview feature อยู่
- Drizzle ถึงจะซัพพอร์ต Views และ RLS แต่ยังคงไม่ซัพพอร์ตการ declare Postgres Function
ผมจึงตกอยู่ในสถานการณ์ที่ว่า เครื่องมือก็มีหลายตัวให้ใช้ แต่ไม่ครบเครื่องสักตัว
สุดท้ายผมก็ต้องเขียน script เอาเอง ที่ช่วยให้ผมสามารถ declare พวก views/functions/policies ไว้ในโฟลเดอร์ แล้วให้ script มันตรวจจับการเปลี่ยนแปลงเพื่อไปสร้างเป็น migration file เพื่อใช้กับ Supabase CLI อีกที (การทำงานคล้ายๆ srtd)
ซึ่งจริงๆ ปัญหา migration นี่ ผมเคยเจอมาตั้งแต่เมื่อปีที่แล้ว ก็รู้สึกเศร้าที่ผ่านมาปีนึงแล้วยังไม่มีอะไรดีขึ้นในจุดนี้
ตอนที่ 9: etc.
Testing
โปรเจคนี้ เราไม่ได้ทำระบบ LMS ทั้งหมดก่อนเปิดโครงการ แต่ทำระบบเท่าที่จำเป็นต้องใช้ในแต่ละช่วงก่อน (ตัวอย่างเช่น ช่วงที่เปิดให้ลงทะเบียนเรียน ระบบเราก็มีแค่หน้าลงทะเบียนเรียนเท่านั้นเลย ส่วนระบบที่เหลือ “ไว้ค่อยทำทีหลัง” ก็ค่อยๆ ทยอย implement ตามความต้องการใช้งาน) ที่ทำแบบนี้ ก็เพื่อที่เมื่อเราเริ่มทำฟีเจอร์ เรามีข้อมูลประกอบการตัดสินใจในการพัฒนาต่างๆ เยอะที่สุด
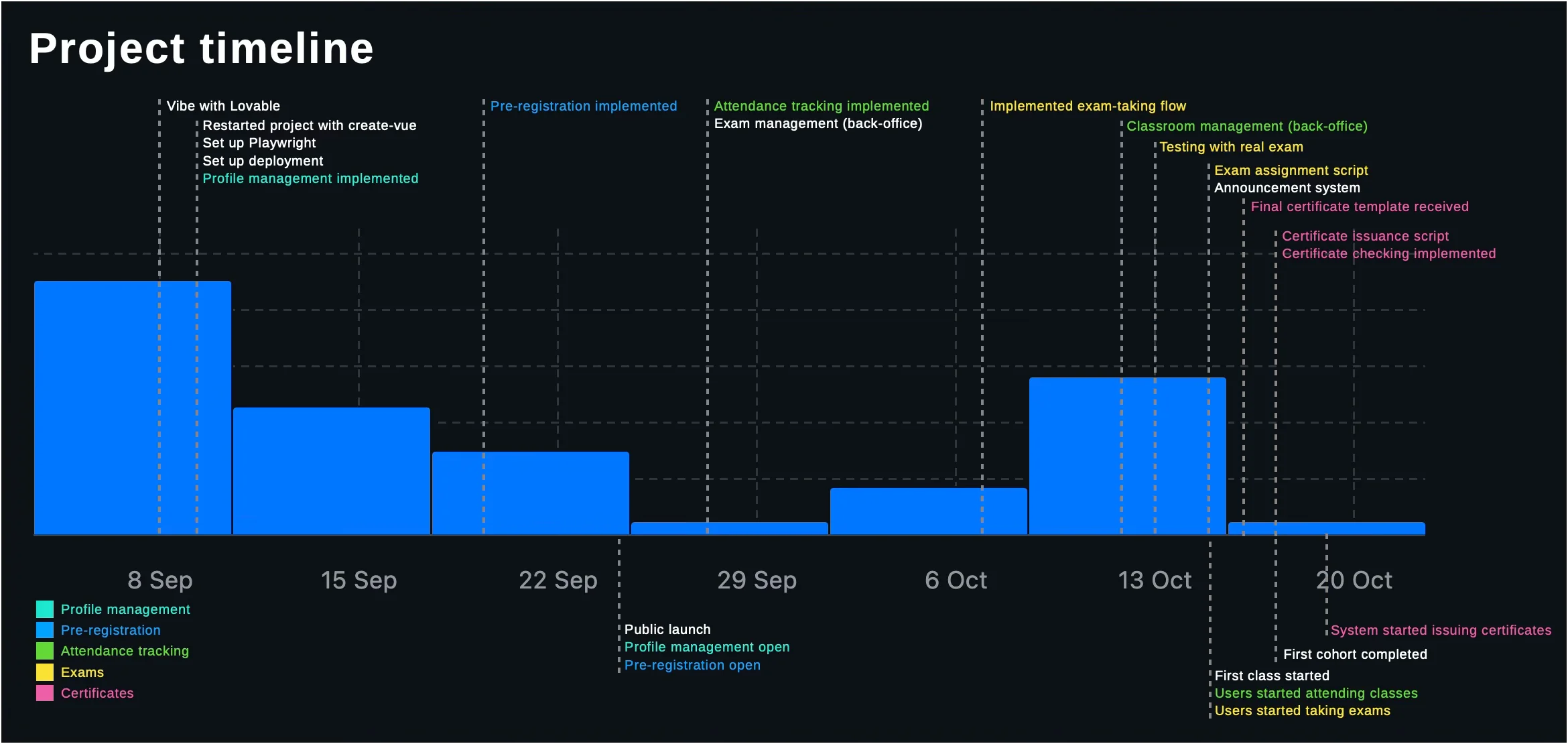
Project timeline — ข้อความด้านบนเป็นกราฟเป็น development activities; ส่วนข้อความด้านล่างกราฟเป็น milestone ต่างๆ ของโครงการ นอกจากนี้ระหว่างทาง ก็มีการแก้โค้ด + refactor บ่อยมากๆ (โดยเฉพาะช่วงที่มีผู้ใช้เข้าเรียนจริง ก็ได้รับ feedback มาแก้ไขเรื่อยๆ) ตัวอย่างเช่น:
มีผู้ใช้จำนวนนึงที่ใช้ In-app browser ของ LINE หรือ Facebook Messenger ในการเข้าระบบ ซึ่งจะไม่สามารถใช้งาน Sign In with Google ได้ ก็ทำฟีเจอร์ detect webview แล้วขึ้นข้อความแนะนำให้เปิดใน browser ปกติแทน
คอมพิวเตอร์ผู้ใช้จำนวนนึง system clock ผิด ทำให้เมื่อถึงเวลาเข้าเรียนไม่แสดงปุ่มเข้าเรียน (แปลกใจที่ปี 2025 แล้วยังต้องมา handle case พวกนี้อยู่) ก็ต้อง deploy Postgres function สำหรับเช็คเวลา server เพื่อเอามาคำนวณเวลาปัจจุบันเพิ่ม
ตัวอย่าง Postgres function สำหรับเช็คเวลา server
CREATE OR REPLACE FUNCTION public.get_server_time() RETURNS jsonb LANGUAGE plpgsql SECURITY DEFINER SET "search_path" TO '' AS $$ BEGIN RETURN jsonb_build_object( 'server_time', NOW(), 'server_time_iso', to_char(NOW() AT TIME ZONE 'UTC', 'YYYY-MM-DD"T"HH24:MI:SS"Z"'), 'server_timezone', current_setting('TIMEZONE') ); END; $$; -- Allow anyone to call this function (even unauthenticated users) GRANT EXECUTE ON FUNCTION public.get_server_time() TO anon, authenticated;
แม้ว่าฟีเจอร์ต่างๆ “ไว้ค่อยทำทีหลัง” ตอนใกล้ๆ จะใช้งานจริง แต่ สิ่งที่ผมคิดว่า “ไว้ค่อยทำทีหลัง” ไม่ได้เลย คือ Automated testing และ Continuous delivery pipeline ซึ่งมีตั้งแต่วันแรก
Automated testing ทำให้ทุกๆ ครั้งที่ผมแก้โค้ด ผมมั่นใจได้ว่า ฟีเจอร์ต่างๆ ที่ทำไปแล้วยังคงทำงานได้ปกติ ซึ่งช่วยให้ผมกล้า refactor โค้ดได้แบบไม่ยั้งมือเลย
โปรเจคนี้ผมใช้ Playwright เขียน black-box test suite ทำให้ทุกครั้งที่ผมแก้โค้ด ไม่ว่าจะเยอะขนาดไหน ผมสามารถมั่นใจได้ว่า happy path ของฟีเจอร์ต่างๆ ยังคงทำงานได้ปกติ โดยแค่กดรันเทสต์แล้วรอ 1 นาที
ถ้าสนใจเรื่อง automated testing ผมเคยมีพูดเกี่ยวกับเรื่อง black box testing ครับ:
โค้ด Black-box test ของโปรเจคนี้ยาวไม่ถึง 400 บรรทัด แต่เป็น 400 บรรทัดที่คุ้มค่ามากๆ… ผมใช้เทคนิค Page Objects เพื่อทำให้เทสต์เขียนง่าย และ maintain ง่าย สามารถดูโค้ดของ test suite ได้ที่ลิงก์นี้ครับ:
litelms.spec.tshttps://gist.github.com/dtinth/835d611ee3fc132d2f22decfa067bb69
Email testing: ระหว่างที่ทำ local development ตัว Supabase CLI จะรัน Mailpit ให้ด้วย ทำให้สามารถจำลอง flow การล็อกอินด้วยอีเมลแบบ passwordless ได้ง่ายๆ เลย โดยการล็อกอินด้วยอีเมล แล้วใช้ API ของ Mailpit ดึงลิงก์ล็อกอินมาใช้ในเทสต์ได้เลย
Self-hosting
ตอนที่เขียนบทความนี้ ยังคง host Supabase ไว้กับ Supabase Pro อยู่ครับ ยังไม่ต้องย้าย infra หลักไป VPS
Supabase มี guide สำหรับ self-hosting โดยใช้ Docker Compose อยู่ แต่พวกค่า secret ต่างๆ จะมาเป็น default หมด ซึ่งเราต้องมาแก้ไขตามคู่มือเอาเอง รวมถึงต้องเซ็ตอัพ SSL เองด้วย… แต่มีโปรเจค supabase-automated-self-host ของคุณ Inder Singh ที่รันคำสั่งเดียวจบเลย เท่าที่ดูก็มีอัพเดตเรื่อยๆ อยู่ คาดว่าถ้าถึงเวลาที่ต้อง self-host จริงๆ ก็น่าจะใช้ตัวนี้
Supabase dashboard
ชอบที่เราสามารถสร้าง Custom Report โดยใส่ SQL query เองได้ ใน Dashboard ของ Supabase เลย ทำให้ไม่ต้องไปใช้พวก Metabase เพิ่ม
Background jobs
ระบบที่ออกแบบมา คือให้การเข้าเรียน การสอบ และการออกเกียรติบัตร/วุฒิบัตร แยกกันอย่างสิ้นเชิง เพื่อความยืดหยุ่น — แปลว่าต้องมี background job ที่คอยมาทำงานพวกนี้ คือ
- คอยเช็คว่าผู้เรียนคนไหนเข้าเรียนครบตามเงื่อนไขบ้าง เพื่อปลดล็อกข้อสอบ
- คอยเช็คผลสอบว่าผู้เรียนคนไหนสอบผ่านบ้าง เพื่อออกเกียรติบัตร
- คอยเช็คว่าผู้เรียนคนไหนมีสิทธิ์ได้วุฒิบัตรบ้าง เพื่อออกวุฒิบัตร
ซึ่งทีแรกก็คิดว่า implement เป็น SQL ดีไหม (แต่จะเขียน SQL ยังไงให้มัน generate PDF…? จริงๆ Postgres Function สามารถยิง HTTP request ไป service อื่นๆ ได้ แต่คิดไปคิดมาก็อาจจะยัง) สุดท้ายก็เลือกเขียนเป็นคำสั่ง TypeScript แล้วเอามารันบน VPS แทน คุ้นมือกว่า
etc.
เรื่อง DB migration มีตัวนึงที่ได้ยินแต่ยังไม่ได้ลองคือ squitch
เจออีกปัญหาคือ เวลาที่ backoffice query ข้อมูลที่ซับซ้อนมากๆ (เช่นสรุปผลว่ามี user กี่คน ที่ลงเรียนครบทุกหน่วยการเรียนรู้ในคอร์สนี้บ้าง — ซึ่งต้องเอาข้อมูลจาก 4 table มารวมกัน) ส่งผลให้ database ช้าทั้งระบบจนกระทบผู้ใช้งานหน้าบ้านด้วย
- Firebase ไม่มีปัญหานี้ เพราะทำ compute-intensive query ไม่ได้ ต้อง denormalize ท่าเดียวถ้าอยากวิเคราะห์ (denormalize นี้รวมถึงการ ETL ข้อมูลไปไว้ที่อื่นในรูปที่ query ได้ง่ายขึ้นด้วย เช่นถ้าจะทำ Full-Text Search ใน Firebase เขาก็แนะนำให้ใช้ Elasticsearch หรือ Algolia แทน… Firebase ไม่รับจบ)
- วิธีแก้ในฝั่ง Supabase ถ้าไม่อยาก denormalize ก็คือ เปิด Read Replica ขึ้นมา เป็น DB ที่มีข้อมูลเหมือนกับ DB หลัก แต่…
- ใช้สำหรับอ่านอย่างเดียว (เราจะได้ API endpoint แยกมา ที่สามารถสั่งได้แค่ GET requests)
- ไม่ว่าจะ query compute intensive ขนาดไหน ก็ไม่ส่งผลกระทบกับ DB หลัก
- ข้อมูลใน read replica อาจจะ delay ไปสักพัก (เรียกว่า replication lag)
- ต้องใช้ Compute Size Small ขึ้นไป (ราคาเริ่มต้น $15/เดือน)
- การเปิด replica จะทำให้ค่าใช้จ่าย DB เพิ่มขึ้น 2 เท่า เพราะ replica จะใช้ compute size เดียวกันกับ DB หลัก — ไม่สามารถเลือกใช้ compute size ที่เล็กกว่าได้
Conclusion
จากสารพัดปัญหาที่กล่าวมา สรุปคือ พอมาใช้ Supabase ก็ช่วยให้เราเก่ง Postgres มากขึ้นจริงๆ ครับ ซึ่งก็น่าจะเป็น skill ที่ติดตัวไปใช้กับโปรเจคอื่นๆ ที่ใช้ Postgres ได้อีกเยอะเลย
สุดท้ายจึงคิดว่า ตัดสินใจถูกแล้วที่เลือกใช้ Supabase เป็น backend ของระบบนี้ครับ แม้จะมี pain point อยู่บ้างตามที่กล่าวมา แต่ก็มีทางออกครับ นอกจากนี้ยังมีข้อดีอื่นๆ อีก เช่น:
- มี Supabase dashboard ช่วยให้ไม่ต้อง implement reporting บางหน้าเอง
- มี AI assistant ช่วยเขียนโค้ด SQL ได้ดีมาก ถามคำถามเกี่ยวกับข้อมูลเป็นภาษาอังกฤษใน dashboard ได้เลย
- สามารถขึ้นหน้า report ใน backoffice ที่มีข้อมูลเรียลไทม์ได้ โดยไม่ต้อง denormalize ข้อมูล แบบที่ต้องทำเวลาใช้ Firebase
และหลังจากผ่านประสบการณ์นี้ ก็น่าจะช่วยให้ใช้ Supabase ได้ effective ขึ้นในอนาคต