รู้สึกดีใจที่ปัจจุบันมี movement เรื่อง Open Data ในไทยเยอะขึ้นกว่าเมื่อก่อนมาก… ทีนี้ข้อมูล open แล้ว แต่มันดึงมาวิเคราะห์ได้ง่ายขนาดไหน?
สมัยก่อนเรียนวิชา Database Systems กว่าจะได้ลองเล่นกับมัน ก็ต้องโหลดโปรแกรมฐานข้อมูลมาติดตั้งใส่คอมก่อน แล้วก็ import sample data เข้าระบบเอง ถึงจะ query ได้ กว่าจะได้เรียนรู้จริงๆ จนถึงจุดที่เห็นพลัง ประโยชน์ และความสนุกของการเล่นกับระบบฐานข้อมูล ต้องผ่านขั้นตอนต่างๆ ที่ไม่ค่อยสนุกเท่าไหร่หลายอย่างมาก (ยังไม่นับเรื่องเรียนรู้ภาคทฤษฎี)
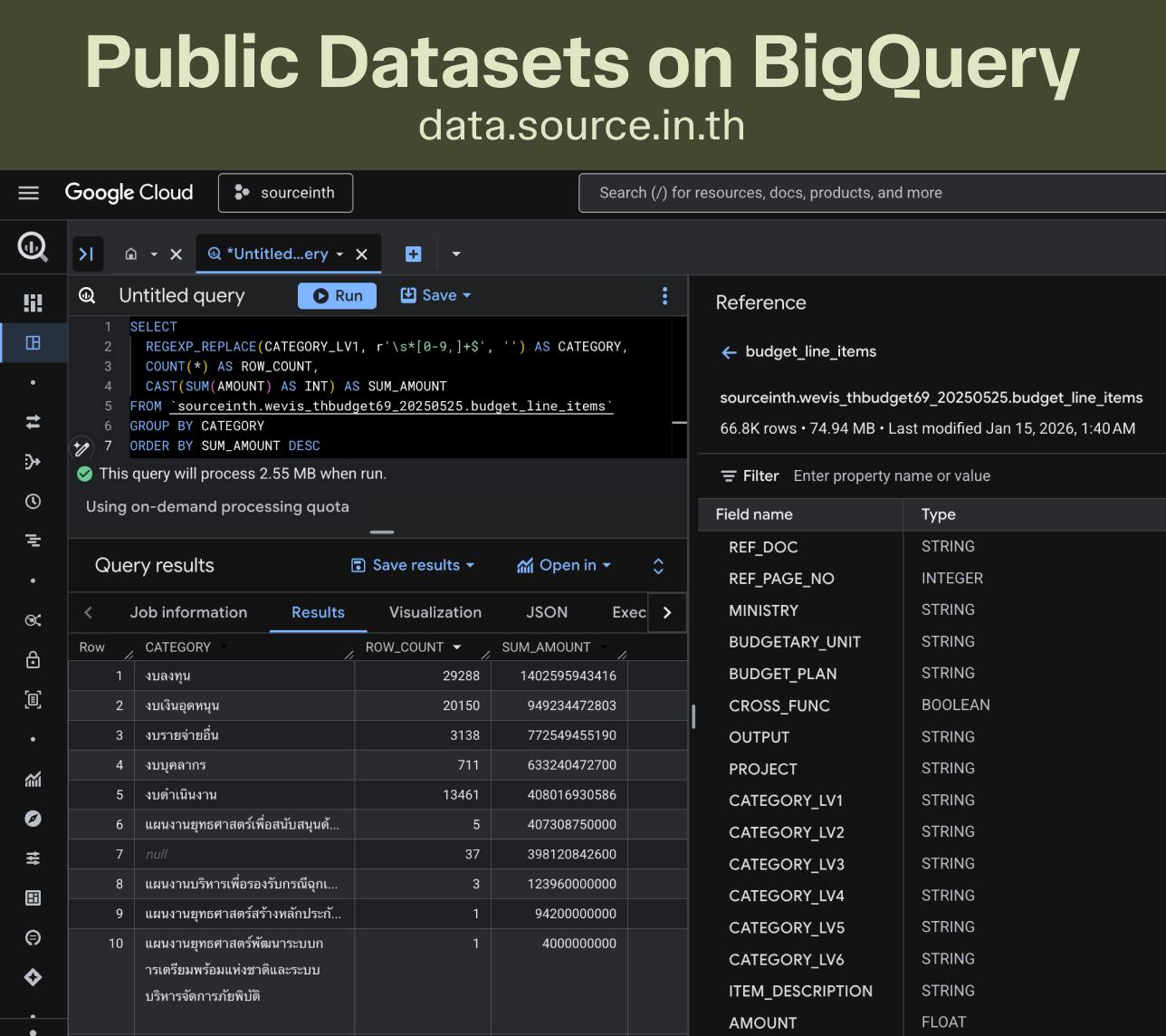
ภาพนึงที่ผมอยากเห็นคือ คนที่สนใจเรื่อง Data Science และอยากศึกษาเกี่ยวกับ DB หรือภาษา SQL สามารถเปิดเว็บแล้วเข้ามา query ข้อมูลสาธารณะที่ตัวเองสนใจได้เลย โดยไม่ต้องติดตั้งโปรแกรมอะไรเพิ่มเติม — เครื่องมือนึงที่ผมพบว่าตอบโจทย์นี้เป๊ะๆ แถมใช้ฟรีด้วย คือ Google BigQuery ครับบ (ตัวอย่างในรูป คือดึงข้อมูลงบประมาณ 2569 ให้จัดอันดับตามหมวดหมู่)
วิธีดึงข้อมูลจาก public dataset:
- เข้าไปที่ BigQuery Sandbox — แค่มี Google Account ก็ใช้งานได้เลย ไม่ต้องผูกบัตร
- เข้ามาแล้วสามารถกด New Query แล้วเขียน SQL เพื่อดึงข้อมูลจาก public dataset ได้ทันทีเลย (หรือจะสร้าง dataset ของตัวเองก็ได้)
โดยใน 1 เดือน สามารถประมวลผลข้อมูลได้ฟรี 1 TB (ถ้าเกิด query ครั้งละ 10MB ก็จะสามารถดึงข้อมูลได้หนึ่งแสนครั้งต่อเดือน)
ล่าสุดเพิ่งเห็นว่า BigQuery เปิด Region ในไทยแล้วด้วย~ เลยลองเอาข้อมูลงบประมาณปี 69 ที่ WeVis ทำไว้ อัปโหลดขึ้นไป แล้วเปิดเป็น public dataset — ไปลอง query กันได้นะครับบ (ตารางชื่อ sourceinth.wevis_thbudget69_20250525.budget_line_items)
SQL query
SELECT
REGEXP_REPLACE(CATEGORY_LV1, r'\s*[0-9,]+$', '') AS CATEGORY,
COUNT(*) AS ROW_COUNT,
CAST(SUM(AMOUNT) AS INT) AS SUM_AMOUNT
FROM `sourceinth.wevis_thbudget69_20250525.budget_line_items`
GROUP BY CATEGORY
ORDER BY SUM_AMOUNT DESCมองว่าอนาคตถ้าเรามี public dataset อยู่บน BigQuery เยอะๆ ใครอยากรู้เรื่องอะไร ก็สามารถวิเคราะห์ข้อมูลกันได้เลย และก็สามารถแชร์โค้ด SQL ให้คนที่อยากวิเคราะห์เชิงลึกขึ้น สามารถเอาไปถามคำถามตัวข้อมูลต่อเองได้ (ก็คือลด friction จาก curiosity → answer)
ถ้าเห็นประโยชน์ของมันตั้งแต่เนิ่นๆ ก็อาจจะเป็นแรงจูงใจที่ทำให้รู้สึกว่า “มันน่าจะคุ้มที่จะเรียนรู้ทฤษฎี และภาษา SQL ให้ลึกๆ แม่นๆ” มากกว่าเรียนๆ ไปก่อนโดยที่ยังไม่รู้ว่าเมื่อไหร่สิ่งที่เรียนมันจะได้ใช้หรือมีประโยชน์
อย่างเช่น SQL ในรูปตัวอย่าง บางคนอาจจะสงสัยว่าทำไมต้องใช้ REGEXP_REPLACE ด้วย? ถ้าอยากรู้ สามารถลองเอาตรงน้ันออกแล้วไป query ดูได้ฮะ โดยโค้ด SQL ในรูป ผมจะใส่ไว้ในคอมเม้นต์ฮะะ
ข้อจำกัดของ BigQuery Sandbox ตัวฟรี และค่าใช้จ่ายเมื่อผูกบัตร
ถ้ายังไม่ผูกบัตร:
- สามารถ query ได้เดือนละ 1 TB
- สามารถสร้าง dataset ของตัวเองได้ โดยมีพื้นที่เก็บข้อมูลฟรี 10 GB
- พวก dataset ที่สร้างทั้งหมด จะมีอายุแค่ 60 วัน หลังจากนั้นจะถูกลบทิ้ง
หลังจากผูกบัตรแล้ว:
- ยังคงมีโควต้าฟรี 10 GB storage และ 1 TB query เหมือนเดิม
- สามารถเก็บ dataset ได้ยาวๆ ไม่ถูกลบอัตโนมัติแล้ว
กรณี query จาก public dataset ใครเป็นคนจ่าย? แบ่งเป็น 2 ส่วน:
- ค่า storage — เจ้าของ dataset จ่าย (ถ้าใช้พื้นที่ไม่ถึง 10 GB ก็ฟรี)
- ค่า query — คนที่กด query จ่ายค่าประมวลผลข้อมูล
- BigQuery region ไทย ถูกกว่าสิงคโปร์ 11.11% ครับ
Public dataset อื่นๆ บน BigQuery
ใน BigQuery Studio สามารถกด Add Data → Public Datasets เพื่อดูชุดข้อมูลต่างๆ ที่อยู่ในโครงการ “Google Cloud Public Dataset Program” ได้ ซึ่งปัจจุบันมีกว่า 300 dataset ให้ query
แต่จริงๆ แล้ว ใครๆ ก็สามารถเปิด dataset เป็น public โดยไม่ต้องเข้าโครงการของ Google อย่างเป็นทางการก็ได้ โดยการ:
- ไปที่ Dataset → Share → Manage permissions → Add principal
- ใส่ role “BigQuery Data Viewer” ให้ “allUsers”
ตัวอย่างโครงการที่แชร์ dataset ด้วยวิธีนี้ ก็เช่นโครงการ GH Archive ที่มีการเก็บข้อมูล Public Activity ทั้งหมดที่เกิดขึ้นบน GitHub ตั้งแต่ปี 2011
อีกโปรเจคนึง (อันนี้อาจจะ niche หน่อย) คือผมเล่นดนตรีออนไลน์ผ่านโปรแกรม Jamulus1 — ผมเลยทำระบบเก็บสถิติเกี่ยวกับเซิร์ฟเวอร์สาธารณะไว้ โดยข้่อมูลของแต่ละวันจะอัปขึ้น BigQuery เป็น public dataset ทีนี้อยากรู้อะไรก็วิเคราะห์เอาได้เลย เช่น
- Q: เมืองไทยเล่น Jamulus กันเยอะไหม?
- A: เยอะเป็นอันดับสองของโลกในปี 2025 (ขึ้นจากอันดับ 3 ในปี 2024)
- Q: เล่นเยอะขนาดไหน?
- A: ปี 2025 นับ playtime รวมกัน 33580 ชั่วโมง (ขึ้นจาก 17937 ชั่วโมง)
ตัวอย่าง SQL query ดูจำนวนชั่วโมงการเล่น Jamulus ในแต่ละประเทศ ปี 2025
WITH daily_rollup AS (
SELECT client_name, date, server_country, SUM(hours_seen) AS hours_seen
FROM `dtinth-storage-space.jamulus.clients`
WHERE (date >= '2025-01-01' AND date < '2026-01-01')
AND client_instrument NOT IN ('Streamer', 'Recorder')
AND client_name NOT IN ('No Name', '')
AND client_name NOT LIKE '% BRB'
AND client_name NOT LIKE '% AFK'
GROUP BY client_name, date, server_country
)
SELECT server_country, SUM(hours_seen) AS hours_seen
FROM daily_rollup
WHERE hours_seen < 12 -- If connected more than 12 hours per day, most likely bot/idler
GROUP BY server_country
HAVING hours_seen > 16
ORDER BY hours_seen DESCข้อควรระวังนึงคือ public dataset บางชุด ขนาดใหญ่มากๆ (หลัก petabyte เลย) ก่อนหน้านี้มีข่าวว่ามีคนลองไป query ข้อมูลจาก public dataset ของ Solana แล้วต่อมา Google ส่งบิลเก็บเงิน query ละประมาณ $5000… ถ้าผูกบัตรไว้แล้วระมัดระวังกันด้วยฮะ
โปรเจค data.source.in.th
นอกจากชุดข้อมูล wevis_thbudget69_20250525 โปรเจค data.source.in.th มีชุดข้อมูลอื่นๆ ที่เคยอัปโหลดไว้เมื่อปี 2024 ด้วย
・ lis_20240729 กับ msbis_20240718 (ข้อมูลจากระบบสารสนเทศด้านนิติบัญญัติ รายงานและบันทึกการประชุม ที่เผยแพร่ในงาน Open Parliament Hackathon 2024) ・ thailand_geography (ข้อมูลจังหวัด–อำเภอ–ตำบล–รหัสไปรษณีย์) ยังไงสามารถไปดูที่เว็บไซต์ได้ครับ (ลิงค์ในคอมเม้นต์) และก็ถ้าใครมี dataset ที่คิดว่าน่าแอดเพิ่ม เปิด Issue บน GitHub มาได้ครับบ
Footnotes
ถ้าใครเคยเห็นคนเล่นดนตรีสดกันออนไลน์ใน TikTok โดยที่แต่ละคนอยู่กันคนละที่ แต่เสียงไม่ดีเลย์ ส่วนมากก็คือเล่นกันผ่านโปรแกรมนี้ ↩