LLM กับข้อสอบ O-NET ม.6
New benchmark available
This post has not been updated since June 2024. Check out AI vs Thai Exams project for a more comprehensive and up-to-date benchmark of LLMs on Thai exams.
ช่วงหลังๆ มีโมเดล LLM ตัวใหม่ๆ ปล่อยออกมาให้เล่นเยอะมาก ทั้ง GPT-4o, Gemini 1.5, Claude 3.5 จึงสงสัยว่าตัวไหนที่ทำงานกับภาษาไทยได้ดีที่สุดตอนนี้
จำได้ว่าไม่นานมานี้ ทาง SCB10X ปล่อย dataset ThaiExam มา เป็นชุดข้อมูลที่รวมข้อสอบต่างๆ เอาไว้ใช้เทียบความรู้ความสามารถของโมเดลภาษา
เลยลองเอาคำถาม O-NET ม.6 ปี 2564 ที่อยู่ในนั้นมาลองถามโมเดลใหม่ๆ ที่เจ้าใหญ่ๆ เพิ่งปล่อยออกมาดู…
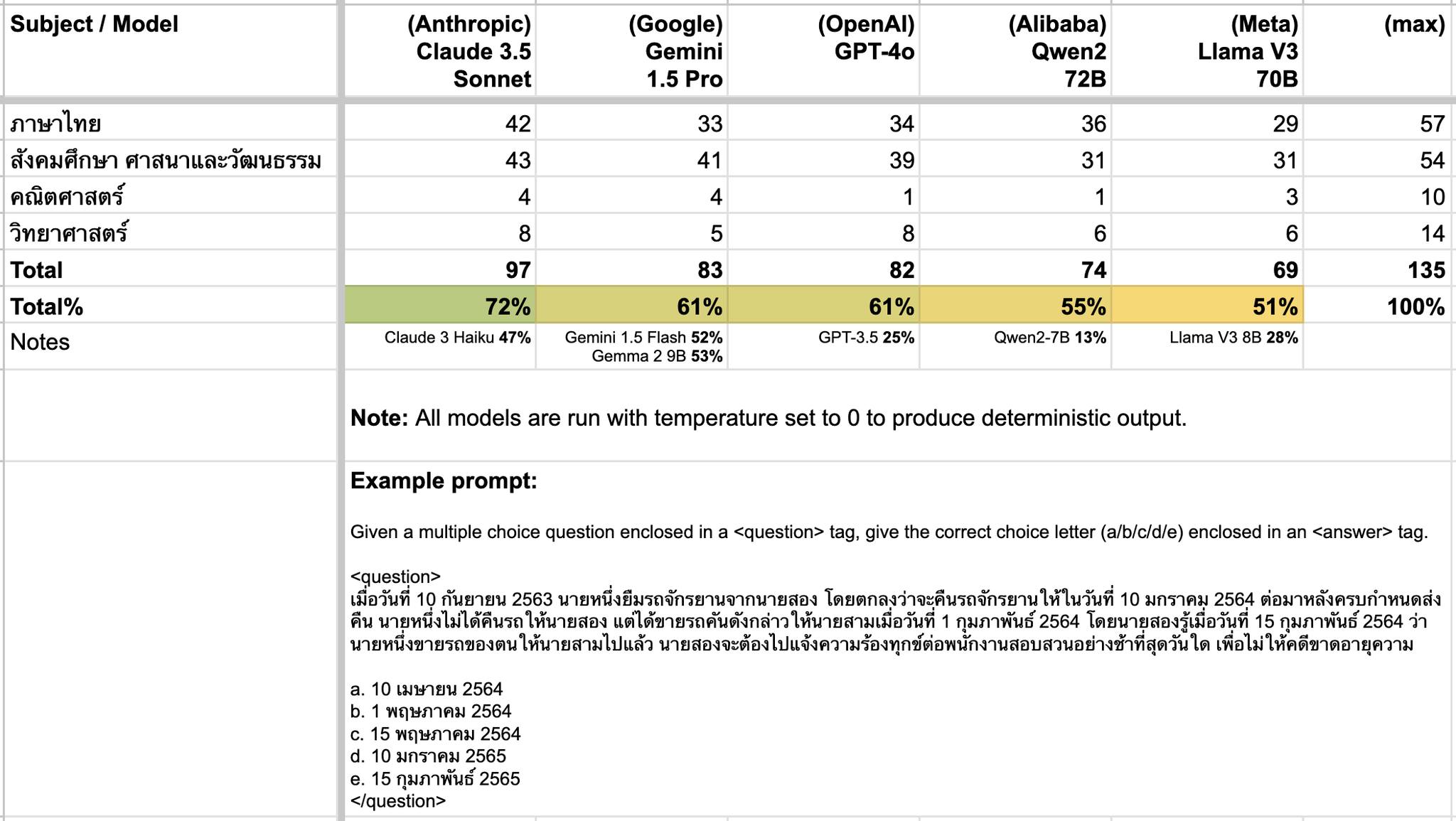
พบว่า
โมเดล Claude 3.5 Sonnet ทำคะแนนได้ดีสุดตอนนี้ อยู่ที่ 72%
ถ้านับเฉพาะโมเดลที่เอามารันบนเครื่องตัวเองได้ (สามารถใช้งานออฟไลน์ได้) ล่าสุด Google เพิ่งปล่อยโมเดล Gemma 2 ออกมาให้โหลดกัน ซึ่งขนาด 9B เล็กพอที่จะรันบนเครื่อง MacBook M1 (16 GB) ผ่าน Ollama ได้ ทำคะแนนได้เยอะที่สุดเท่าที่ลองมา คือ 53%
แต่ถ้ามีพื้นที่กับ VRAM เยอะพอที่จะรัน Gemma 2 ขนาด 27B ได้ ตัวนั้นทำคะแนนได้ดีกว่านิดหน่อย คือ 59%
ของค่าย OpenAI โมเดล GPT-4o กับ GPT-3.5 คะแนนต่างกันมาก (61% vs 25%)
(จากข้อมูลสถิติของ สทศ คะแนนเฉลี่ย O-NET ในปี 2564 อยู่ที่ ~39% โดยปรับสัดส่วนจำนวนข้อตามข้อมูลใน ThaiExam และไม่นับคะแนนวิชาภาษาอังกฤษ)
ช่วงนี้คนพูดถึง Phi-3 ของค่าย Microsoft กับพอสมควร แต่โมเดลนั้นแทบไม่ได้ train บนข้อมูลภาษาไทยเลย ทำคะแนนได้แค่ 23% จึงไม่ได้ใส่ในตาราง
(จริงๆ นอกจาก O-NET ตัว dataset ยังมีข้อมูลจากข้อสอบอื่นๆ ด้วย ได้แก่ IC, TGAT, TPAT-1, A-Level แต่โพสต์นี้ทดลองแค่ O-NET เพราะขี้เกียจละ)
(และก็ วิธีที่ผม benchmark จะต่างจากวิธีที่ SCB10X ทำ เพราะตอนที่ลองทดสอบ ผมอ่านแต่ตัว dataset ไม่ได้อ่านวิธีที่จะเอาไปใช้ให้ถูกต้อง และเข้าใจว่าปกติจะใช้ HELM ซึ่งผมใช้ไม่เป็นและขี้เกียจเรียน ดังนั้น prompt และ model parameter ต่างๆ จะไม่เหมือนกัน ตัวเลขคะแนนที่ได้ก็อาจจะแตกต่างกันออกไป นอกจากนี้บางโมเดลผมขี้เกียจรันบนเครื่องตัวเอง เลยไปหา API ใช้ ใครว่างๆ ลอง benchmark ใน HELM แล้วแชร์ผลลัพธ์มาดูได้ครับ จะได้มีผล benchmark เยอะขึ้น และอยู่ในสภาพที่ดีกว่านี้)